
The Goal
There are a few things we definitely want to know about each article published on KDNuggets.
- Article Title
- Date published
- Author (when applicable)
- Tags (might see if we can predict tags based on article text later on)
- The article body, obviously
We also may be able to get a little more information from some articles. Certain articles have info in these miniature summaries that come before the main article body. It may or may not be repeated information but we might as well pull it too and shunt it into its own column.
There's also sometimes extra information about the author, like the company they work for, that we can pull, though it isn't really essential for me personally.
So the first step for us will be to scout out a few real examples of article pages on the website and retrieve the 'path' that will allow our spider to find and extract the specific text that we want for each piece of information we need. I'm gonna use raw XPaths today because that seems simplest to me. If you prefer to bring in beautiful soup for targeting info, that's great, more power to you.
But first, I'll insert a brief outline of or spider components do that it doesn't seem out of the blue later when we talk about items and pipelines.
Spider Components
For an introduction on how to install scrapy, create a spider, etc., please check out the Scrapy docs.
For clarity and future reference, the Python you'll see all comes from one of these files. We'll spend most of our time actually building the spider itself in kdn_spyder.py.
scrapy.cfg
kdn_articles/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
kdn_spyder.py
Choosing XPaths
This is another part where you can totally do it your own way, but it only takes a few seconds to begin finding possible tags and/or attributes specific to the info you want from a webpage just using devtools and (optionally) an extension like Chrome's XPath Helper.
https://www.kdnuggets.com/2020/03/mature-machine-learning-team.html
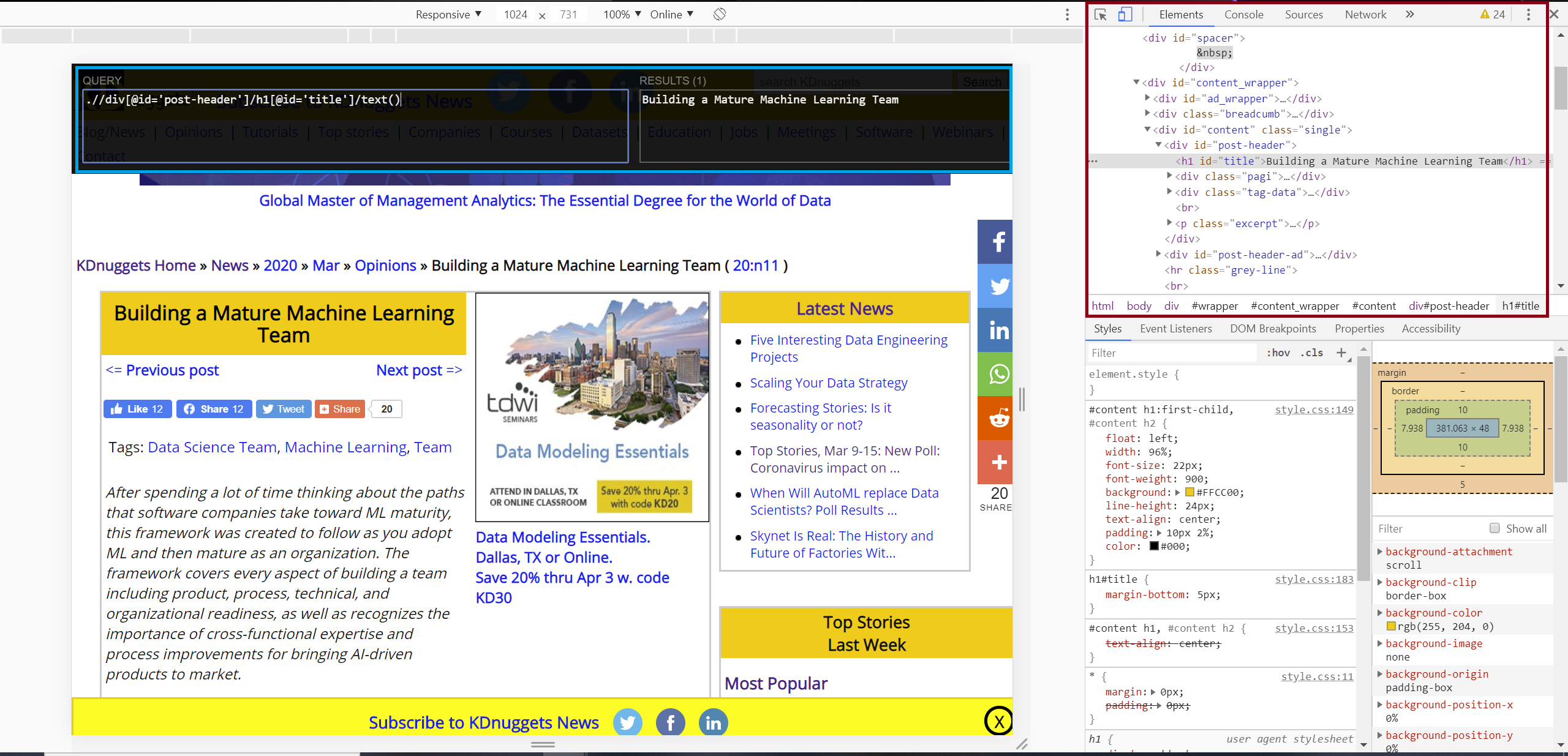

So you can easily find a "path" via the devtools of whatever browser you like (Chrome, IE, Edge, Firefox devtools at least are all fairly similar), and then confirm your XPath with something like XPath Helper. We can also check that we have valid and desirable XPaths by testing in the Scrapy Shell later on.
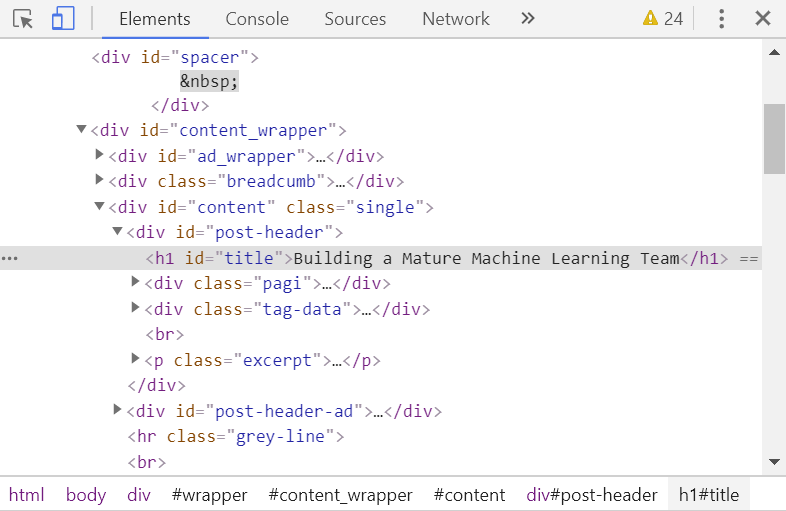
Below I've highlighted in blue examples of text we might want to target specifically with our spider:
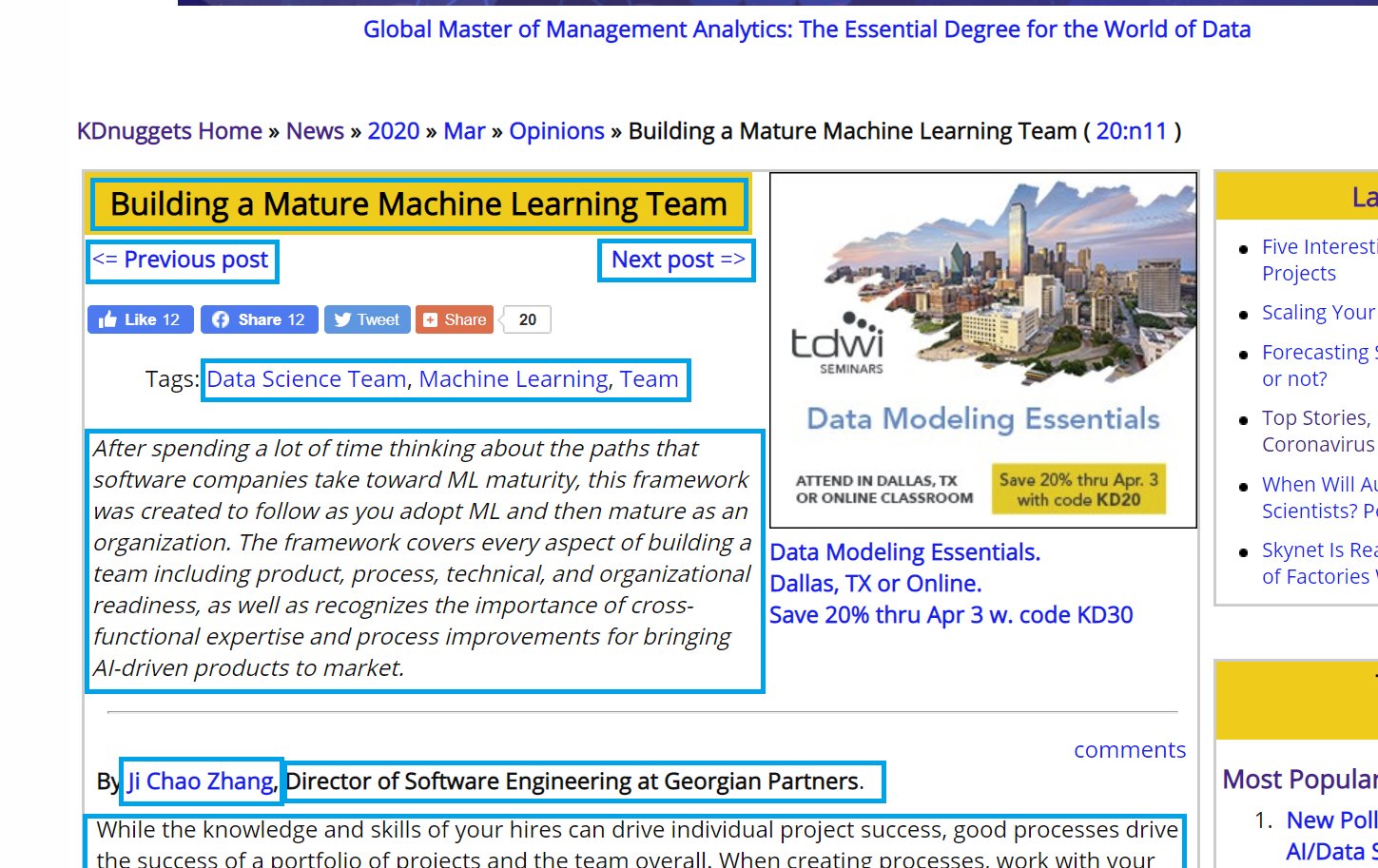
And XPaths I found for the data we want to start with:
- Title: ".//div[@id='post-header']/h1[@id='title']/text()"
- Published Date: ".//div[@class='main_wrapper']/comment()[1]"
- Author: ".//div[@id='post-']/p/b/a/text()"
- Author Info: ".//div[@id='post-']/p/b/text()"
- Tags List: ".//div[@class='tag-data']/a"
- Article Excerpt: ".//p[@class='excerpt']/text()"
- Article Text: ".//div[@id='post-']//text()"
- "Previous" Links: ".//div[@class='pagi-left']/a"
After testing with Scrapy Shell that this works for other pages, it's pretty neat to realize that we can simply look to these XPaths for most KDNuggets articles and pull the same information every time. If we find edge cases or, say, older articles where the tags/attributes don't conform to the same format, we can add some if/else statements into our spider code.
Note that the above XPaths alone aren't enough to get the pretty text we'd like to pipe to our database or dataframe. In the following section we'll actually build out the spider that will take the raw text from KDN's html and clean it a bit before yielding an Item for each page we scrape.
Building the Spider
Let's start by building on the XPaths we've retrieved above.
Say you create your first project and spider with the following commands:
scrapy startproject kdn_articles # Creates the project directory, including scrapy.cfg, settings.py, etc. files (see docs)
...
scrapy genspider kdn_spyder kdnuggets.com # Creates a spider with the name 'kdn_spyder' and domain 'kdnuggets.com'
The default spider file you begin with will look something like this:
# kdn_spyder.py
# -*- coding: utf-8 -*-
import scrapy
class KdnSpyderSpider(scrapy.Spider):
name = 'kdn_spyder'
allowed_domains = ['kdnuggets.com']
start_urls = ['http://kdnuggets.com/']
def parse(self, response):
pass
We'll end up adding import statements and changing the start_urls, but let's dive right into the parse function and look at how to use scrapy to gather the text we saw on the webpage for each piece of info we want to scrape.
We're ultimately going to be yielding Scrapy Items from parse since we want this to be a recursive function passing data to our database along with each page scrape, but for now we'll just assign each piece of info to a variable, and discuss Items in a minute.
...
def parse(self, response):
selector = Selector(response)
title = selector.xpath(
".//div[@id='post-header']/h1[@id='title']/text()").extract_first()
...
Again, this is not the only way to do it, but technically using Selectors + XPath/CSS expressions is faster than using bs4, which is also common and completely valid. I like to define a selector (response=response, the HTTP response) at the beginning of the function as opposed to typing out Selector(response) every time, and simply call selector.xpath(...) or selector.css(...) in order to retrieve the data we need.
With the 'selection' above, we pass the exact XPath we chose from working with devtools (and XPath Helper) to xpath() and then extract the first item (extract_first()) in the list that gets returned. This is my general first attempt when I'm extracting text from within just one html tag. In this case extract_first() will get us a string as opposed to a list of strings with length of 1. It's just simpler to get this step out of the way now in one line.
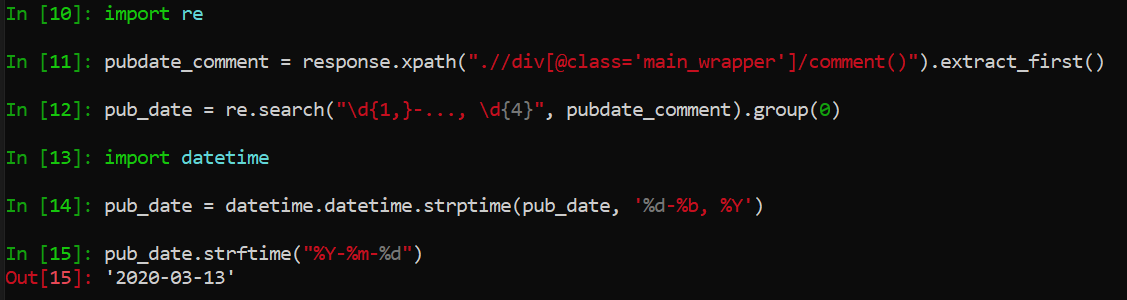
Hopefully this Scrapy Shell snippet clarifies what I mean:

And actually that's all we need to do for our title variable. Let's move on to something that actually requires a (tiny) bit of work:
import re # regex
import datetime
pubdate_comment = response.xpath(
".//div[@class='main_wrapper']/comment()").extract_first()
pub_date = re.search("\d{1,}-..., \d{4}", pubdate_comment).group(0)
pub_date = datetime.datetime.strptime(pub_date, '%d-%b, %Y')
pub_date = pub_date.strftime("%Y-%m-%d")
These articles don't have the published date visible anywhere on the webpage itself (that I could find), so I referenced the html and found that the first comment in the 'main-wrapper' div has the format <!-- publ: __DATE__ -->. Easy enough to extract similar to how we did title, however we also need to get rid of everything but the date itself, and then parse the date into a more useful datetime format.

And so with the re and datetime packages we quickly go from something like "<!-- publ: 13-Mar, 2020 -->" to something like "2020-03-13"
We can follow a similar process of testing with Scrapy Shell for the other variables we want. To keep things brief, here's the extraction I used for the rest:
# Author
author = selector.xpath(".//div[@id='post-']/p/b/a/text()").extract_first()
# Author Info
author_info = ''.join(selector.xpath(".//div[@id='post-']/p/b/text()").extract())
# Tags
tags = ', '.join(selector.xpath(".//div[@class='tag-data']/a/text()").extract())
# Article summary/excerpt
excerpt = selector.xpath(
".//p[@class='excerpt']/text()").extract_first().strip()
# Full article body
post_text = ''.join(selector.xpath(".//div[@id='post-']//text()").extract()).strip()
Notice that we join into one string anything that gets returned as a list of strings. This is because we want each field to have a value that is just one object rather than a list of objects. We can always expand it out again if we need when doing cleaning and analysis later.
I also just leave the full article text as is (after stripping whitespace) because I may find a copy of the text in its original form useful later on when I do text analysis one these articles. I'd rather have to clean it up later than remove something useful before ever even analyzing it.
And that's really about it for the info we need! Next we'll quickly look at Items and the pipeline to our database so it becomes clear what we do with these variables that we've defined.
Items & Fields
So to be as brief as possible, a Scrapy Item class functions something like a Python dictionary object, whereby you can use a {field_name: value} format and easily take data you've scraped and pass it through to a dictionary or some tabular data structure.
All we need to worry about here is matching the Items we create in our kdn_spyder with rows in our database. And actually we're going to create the table the very first time we run this spider so the rest becomes very simple.
First we edit items.py and define a scrapy.Item class. We define a Scrapy Field object corresponding to each piece of info we intend to scrape. These will also each correspond to one column in our eventual database table.
# items.py
class KdnArticlesItem(scrapy.Item):
date_published = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
author_info = scrapy.Field()
tags = scrapy.Field()
excerpt = scrapy.Field()
post_text = scrapy.Field()
Then, back in kdn_spyder.py we define an item (of scrapy.Item class) and simply assign our variables from the section above to item['FIELD_NAME'] instead of just a variable name. We'll also go ahead and replace the default pass with yield item now. So the first part of our parse function will look like this:
# kdn_spyder.py
def parse(self, response):
selector = Selector(response)
# Create Item object
item = items.KdnArticlesItem()
# Date Published
pubdate_comment = response.xpath(
".//div[@class='main_wrapper']/comment()").extract_first()
pub_date = re.search("\d{1,}-..., \d{4}", pubdate_comment).group(0)
pub_date = datetime.datetime.strptime(pub_date, '%d-%b, %Y')
item['date_published'] = pub_date.strftime("%Y-%m-%d")
# Title
item['title'] = selector.xpath(
".//div[@id='post-header']/h1[@id='title']/text()").extract_first()
# Author
item['author'] = selector.xpath(".//div[@id='post-']/p/b/a/text()").extract_first()
# Author Info
item['author_info'] = ''.join(selector.xpath(".//div[@id='post-']/p/b/text()").extract())
# Tags
item['tags'] = ', '.join(selector.xpath(".//div[@class='tag-data']/a/text()").extract())
# Article summary/excerpt
item['excerpt'] = selector.xpath(
".//p[@class='excerpt']/text()").extract_first().strip()
# Full article body
item['post_text'] = ''.join(selector.xpath(".//div[@id='post-']//text()").extract()).strip()
yield item
I like Michael Yin's tutorial on the basics of using Scrapy Items if you're interested, since I won't really be going into the details here.
Item Pipeline & SQLAlchemy
We'll also need to edit settings.py and make a models.py file in the project directory iin order handle the database side of our scrape. Obviously some of this is not necessary if you have a project and want to go straight from the html to pandas or something.
# settings.py
...
BOT_NAME = 'kdn_spyder'
SPIDER_MODULES = ['kdn_spyder.spiders']
NEWSPIDER_MODULE = 'kdn_spyder.spiders'
# We're gonna pass this to SQLAlchemy
CONNECTION_STRING = "{drivername}://{user}:{password}@{host}:{port}/{database}".format(
drivername="DRIVER", # e.g. 'postgresql', 'mysql', etc.
user="USER",
password="PASSWORD",
host="HOST", # often 'localhost'
port="PORT",
database="DB_NAME",
)
...
# custom, setting DOWNLOAD_DELAY to 500ms here.
# the actual delay btw each request will now be a length of time in drawn from
# the random interval [0.5 * DOWNLOAD_DELAY, 1.5 * DOWNLOAD_DELAY] (seconds)
DOWNLOAD_DELAY = 0.5
...
# We'll actually create this pipeline below
ITEM_PIPELINES = {
'kdn_articles.pipelines.KdnArticlesPipeline': 300,
}
...
Next, a new models.py which we create ourselves..
# models.py
from sqlalchemy import create_engine, MetaData, Column, Integer, String, Date, Text
from sqlalchemy.ext.declarative import declarative_base
from scrapy.utils.project import get_project_settings
import logging
DeclarativeBase = declarative_base()
def db_connect():
# DB connection using settings from (above) settings.py
# UTF-8 generally the safest encoding to work with, but still occasionally have to troubleshoot
return create_engine(get_project_settings().get("CONNECTION_STRING"), encoding='utf-8')
def create_table(engine):
table_name = 'kdn_articles'
metadata = MetaData(engine, reflect=True)
table = metadata.tables.get(table_name)
# If kdn_articles table exists in db, then delete and start from scratch
if table is not None:
logging.info(f'deleting {table_name} table')
DeclarativeBase.metadata.drop_all(engine, [table], checkfirst=True)
DeclarativeBase.metadata.create_all(engine)
class KdnArticlesDB(DeclarativeBase):
__tablename__ = "kdn_articles"
# sqlalchemy syntax for defining columns in a DB.
# Note the additional id primary key, not from our item fields
id = Column(Integer, primary_key=True)
title = Column('title', Text(), unique=True)
date_published = Column('date_published', Date())
author = Column('author', String(128))
author_info = Column('author_info', String(256))
tags = Column('description', String(256))
excerpt = Column('excerpt', Text())
post_text = Column('post_text', Text())
This isn't a comprehensive tutorial on Scrapy or item pipelines so if you're curious I recommend looking at the docs, but basically we'll next include a process_item function in pipelines.py that assigns our items coming from our spider, kdn_spyder.py, to the declarative base (KdnArticlesDB) from models.py.
Remember this is all using SQLAlchemy.
# pipelines.py
from sqlalchemy.orm import sessionmaker
from kgn_articles.models import KdnArticlesDB, db_connect, create_table
# This logging section is optional
import logging
logger = logging.getLogger("kdn_spyder_spider")
logger.setLevel(logging.WARNING)
fh = logging.FileHandler('PATH\\IF\\YOU\\PLZ\\python_error_logs\\kdn_spyder_spider_log.txt')
fh.setLevel(logging.WARNING)
logger.addHandler(fh)
class KdnArticlesPipeline(object):
def __init__(self):
"""
Initializes database connection and sessionmaker.
Creates articles table (if not commented out).
"""
engine = db_connect()
# I simply comment this out if I'm just adding to my records
create_table(engine)
self.Session = sessionmaker(bind=engine)
def process_item(self, item, spider):
"""
Save article data in the database.
"""
session = self.Session()
kdndb = KdnArticlesDB()
kdndb.date_published = item['date_published']
kdndb.title = item['title']
kdndb.author = item['author']
kdndb.author_info = item['author_info']
kdndb.tags = item['tags']
kdndb.excerpt = item['excerpt']
kdndb.post_text = item['post_text']
try:
session.add(kdndb)
session.commit()
# Optional:
except UnicodeEncodeError as e:
logger.debug(e, exc_info=False)
raise
except:
session.rollback()
raise
finally:
session.close()
return item
A couple of notes on our pipeline:
- Sometimes we're able to scrape everything we want in one go, in which case including the create_table function is great because we can construct the table and begin populating it at the same time. However sometimes we want to scrape tens, hundreds of thousands or millions of pages and for whatever reason we can't or don't want to let our spider crawl for hours or days uninterrupted. So whenever we want to simply add onto an existing table instead of create a new one, we just comment out the create_table(engine) line in pipelines.py.
- The logging is optional but I just happened to find it useful while testing for this project because I had trouble with encoding errors at first. So it serves as an example of how you COULD add error handling and logging to the process of piping scraped text to a database if you needed to.
Test the Spider
Assuming we haven't made any typos and our XPaths are correct, we are actually all set to test our spider on one url and make sure we can store a single Item in the database table (in addition to creating the table). It's a good idea to test scrape a few singular pages to ensure the spider and pipeline implementations work before adding the code to iterate the process over multiple pages. Makes it more likely that you'll catch any bugs or edge cases that have to do with the scraping and item processing components before introducing another potential source of errors.
So, for reference, our kdn_spyder.py now looks like this. Remember we need our import statements for re, datetime as well, and for now we'll set start_urls to whatever single article page we're testing on.
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import Spider
from scrapy.selector import Selector
from scrapy.loader import XPathItemLoader
from scrapy.loader.processors import Join, MapCompose
import re
import datetime
import kdn_test.items as items
class KdnSpyderSpider(scrapy.Spider):
name = 'kdn_spyder'
allowed_domains = ['kdnuggets.com']
start_urls = ['https://www.kdnuggets.com/2020/03/mature-machine-learning-team.html']
# kdn_spyder.py
def parse(self, response):
selector = Selector(response)
# Create Item object
item = items.KdnArticlesItem()
# Date Published
pubdate_comment = response.xpath(
".//div[@class='main_wrapper']/comment()").extract_first()
pub_date = re.search("\d{1,}-..., \d{4}", pubdate_comment).group(0)
pub_date = datetime.datetime.strptime(pub_date, '%d-%b, %Y')
item['date_published'] = pub_date.strftime("%Y-%m-%d")
# Title
item['title'] = selector.xpath(
".//div[@id='post-header']/h1[@id='title']/text()").extract_first()
# Author
item['author'] = selector.xpath(".//div[@id='post-']/p/b/a/text()").extract_first()
# Author Info
item['author_info'] = ''.join(selector.xpath(".//div[@id='post-']/p/b/text()").extract())
# Tags
item['tags'] = ', '.join(selector.xpath(".//div[@class='tag-data']/a/text()").extract())
# Article summary/excerpt
item['excerpt'] = selector.xpath(
".//p[@class='excerpt']/text()").extract_first().strip()
# Full article body
item['post_text'] = ''.join(selector.xpath(".//div[@id='post-']//text()").extract()).strip()
yield item
After making sure whatever database we're piping to is ready to accept connections, we can run our single-page spider by calling scrapy crawl SPIDER_NAME from within the project directory (kdn_articles).
...\kdn_articles>scrapy crawl kdn_spyder
And we then can view the results of our handiwork! Again, I'm using postgres today; the database name is "weswa".
First, we can see that the table was successfully created as we defined it, including the auto-generated id column. All of the columns are present with the expected data types, and we've set 'title' to be unique, just in case we inadvertantly try to scrape the same article twice at some point. I don't feel like duplicating rows here.
A quick query of the table results as expected (I didn't include every column in the screenshot below to save space, but they're also OK).
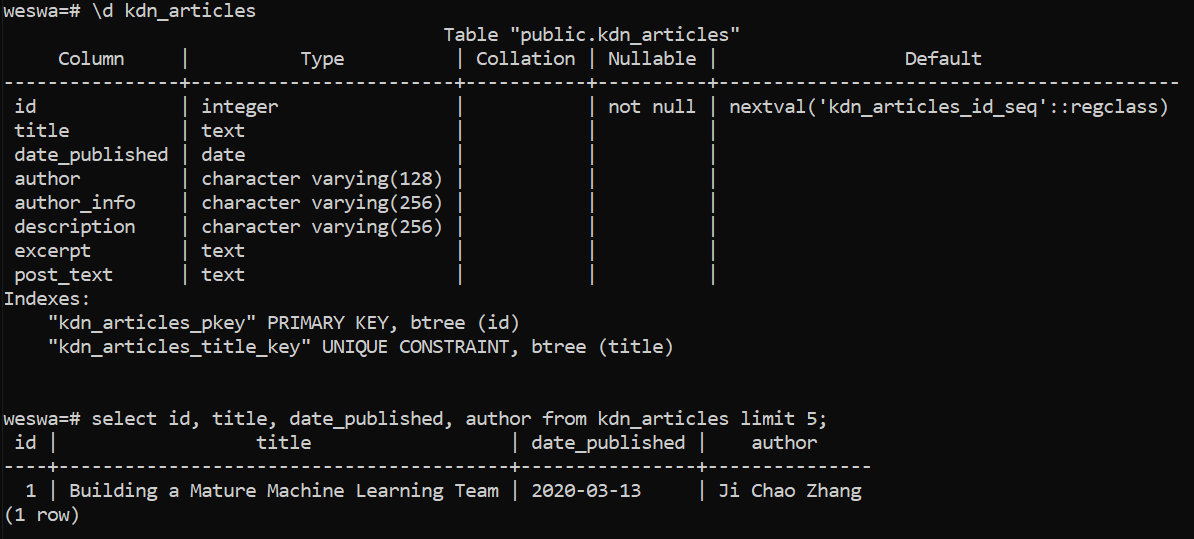
We should try running the spider on a few more article pages just to make sure it's valid for the general KDN article. In order to add to the existing table rather than deleting it and starting over, let's also not forget to comment out the create_table(engine) line in pipelines.py. Assuming we like the table we currently have and don't see any issues with further scraping, it's a method we'll no longer need for this project (thanks to our UNIQUE constraint on article title).
After testing a few urls from a wide range of dates, we begin to notice that certain older articles have different ways of presenting infromation like 'author'. Sometimes author just doesn't exist, but we should try to accomodate edge cases by recognizing patterns and addressing them in the most efficient way.
If you're manually scraping for specific information this is often be a matter of going to the site and inspecting the html of as many cases as possible, although if it seems difficult to find common patterns that can be solved by one or two if statements, then regex is an option, and you can always consider the possibility of just scraping everything with a catch-all and dealing with inconsistencies when it comes time to use the data in whatever your ultimate project is.
For instance with this spider I included a few possible selectors for 'author' that catch nearly all cases, but if author is unclear and ends up as part of 'author_info' that's really fine by me. I don't specifically intend to use the author column in my text analysis module anyway, I'm more interested in the article content, which we're having no trouble scraping.
Page Navigation
Once we're confident that our spider works well in the general sense for individual webpages, it's time to tell it how to navigate from article to article and automatically scrape as many consecutive pages as we tell it to.
Luckily, with scrapy this is as simple as identifying the href attribute of the 'next' page link we want to visit after yielding our item. With something like articles in a digital magazine or newssource like KDNuggets, this may be as simple as finding an index of articles or locating a 'Previous' or 'Next' link, which we will now demo.
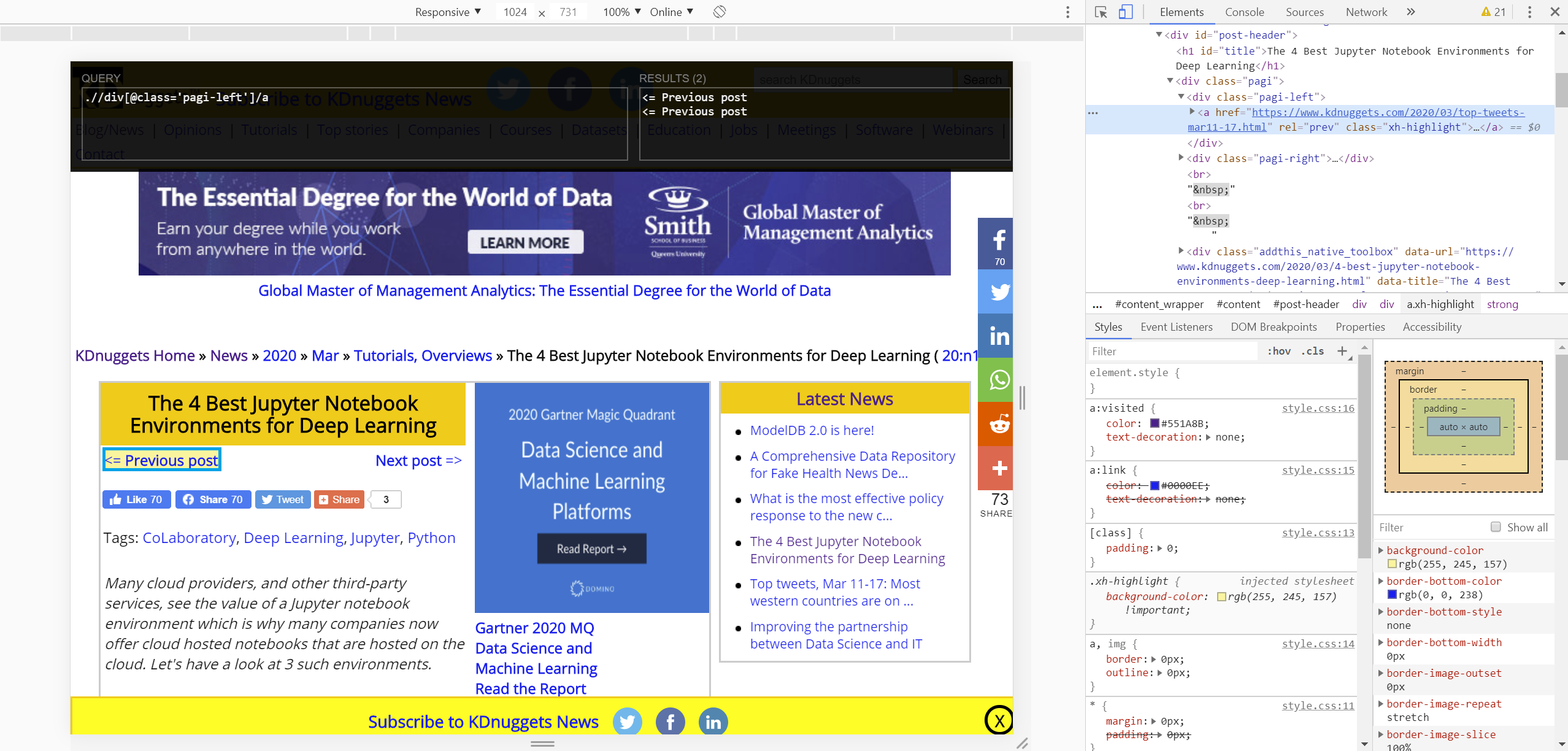
There are actually two instances of this Previous Post link (the other is below the article), but we can just follow the first we find.
And all we need to accomplish this is to add the following to our kdn_spyder.py parse function:
# kdn_spyder.py
...
class KdnSpyderSpider(scrapy.Spider):
...
def parse(self, response):
...
yield item
prev_page = response.xpath(".//div[@class='pagi-left']").css("a::attr(href)").extract_first()
if prev_page:
yield scrapy.Request(
url=response.urljoin(prev_page),
callback=self.parse
)
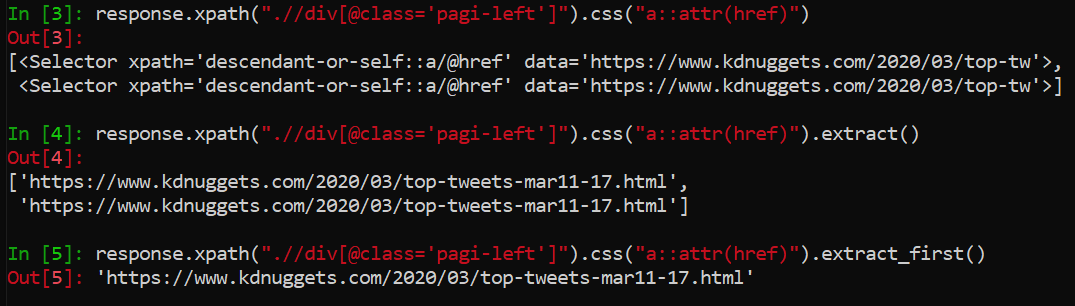
First we get the xpath for the div containing our previous page link(s), and then target/extract the 'a' element href attributes and extract the first we find (they're both the same).
Assuming we actually found a page to link to, we then yield a Scrapy Request with the new url being the href we just extracted and the callback function being the same parse so that the spider repeats this process indefinitely, or rather until it runs into a page without a Previous Page link. Note that generally you might want to use url=response.urljoin(prev_page), as opposed to just url=prev_page, in order to catch relative links. In this particular case I've found it matters for Jan. 2014 and earlier articles, since KDNuggets only began providing absolute URLs with its inter-article links in early 2014.
Run the Spider & Sample Results
For a spider that simply moves from page to page, scraping to fields and yielding one item each iteration, this is pretty much it! We can try running the spider in this form, keeping an eye on its project at first to make sure everything's actually being successfully passed to the database, but if we don't have errors or missing data then we can just "scrapy crawl ..." the spider and let it run as long as it can.
We've set this one up so that it follows the "Previous Post" links, so we need to pass it the most recent article url and let it work backwards in time. I originally decided to go newer to older because when testing I wasn't sure exactly what date KDN switched to completely different format for their website, but the most recent article was easy to find immediatly. Also earlier articles don't have the same info, like tags, so in some regards I care a bit less about earlier articles. A higher proportion of them are ads for job openings and such rather than news-like articles. But I still want the post text for these earlier ones so that we can track trends and topics over time. We'll just have to keep in mind that KDN blew up in the early to mid 2010s, and so some of the older text might not be as high-quality.
So actually running the spider from the terminal...
...\kdn_articles>scrapy crawl kdn_spyder
Should not only iteratively scrape pages but also pipe items one by one into the data table we set up. I pulled just under 10k unique articles with the first run of this spider, and the way we chose our items everything is nicely queryable.
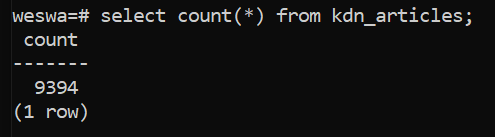

Note this just happens to be a pull from part way through scraping, hence the dates from 2016
Of course with such a small amount of data we can easily just transfer to pandas, clean everything up, and immediately begin analysis. So let's finish this module with a quick look at how to pull data from tables in a database with SQLAlchemy. The subsequent text analysis and topic modeling will be the topic of the next module(s).
import numpy as np
import pandas as pd
# from pull_kdn_data.py
# Using sqlalchemy extract (all) data in from postgresql data table
# 'kdn_articles' and export to a format that we can use for cleaning
# demos in python/pandas
# This and the following cell are only necessary when pulling data from postgres, after that
# we can just use the data stored in csv file (below)
from sqlalchemy import create_engine, MetaData, Table, select
engine = create_engine('postgresql://weswa:PASSWORD@localhost:5432/weswa')
connection = engine.connect()
meta = MetaData()
meta.reflect(bind=engine)
kdn_articles = Table('kdn_articles', meta, autoload=True, autoload_with=engine)
stmt = select([kdn_articles])
results = connection.execute(stmt).fetchall()
kdn_articles_df = pd.DataFrame(
results,
columns=['id', 'title', 'date_published', 'author', 'author_info',
'tags', 'excerpt', 'post_text', 'url']
)
# Store data from db table in csv for future ease of access
kdn_articles_df.to_csv('C:\\PATH\\TO\\FILE\\20_03_kdnarticles.csv',
sep=',', header=kdn_articles.columns,
index=False, encoding='utf-8')
# And now pandas df from the file. After we have the csv,
# the above cells are unnecessary (save the np and pandas imports)
kdn_articles_df = pd.read_csv('C:\\PATH\\TO\\FILE\\20_03_kdnarticles.csv')
kdn_articles_df.head()
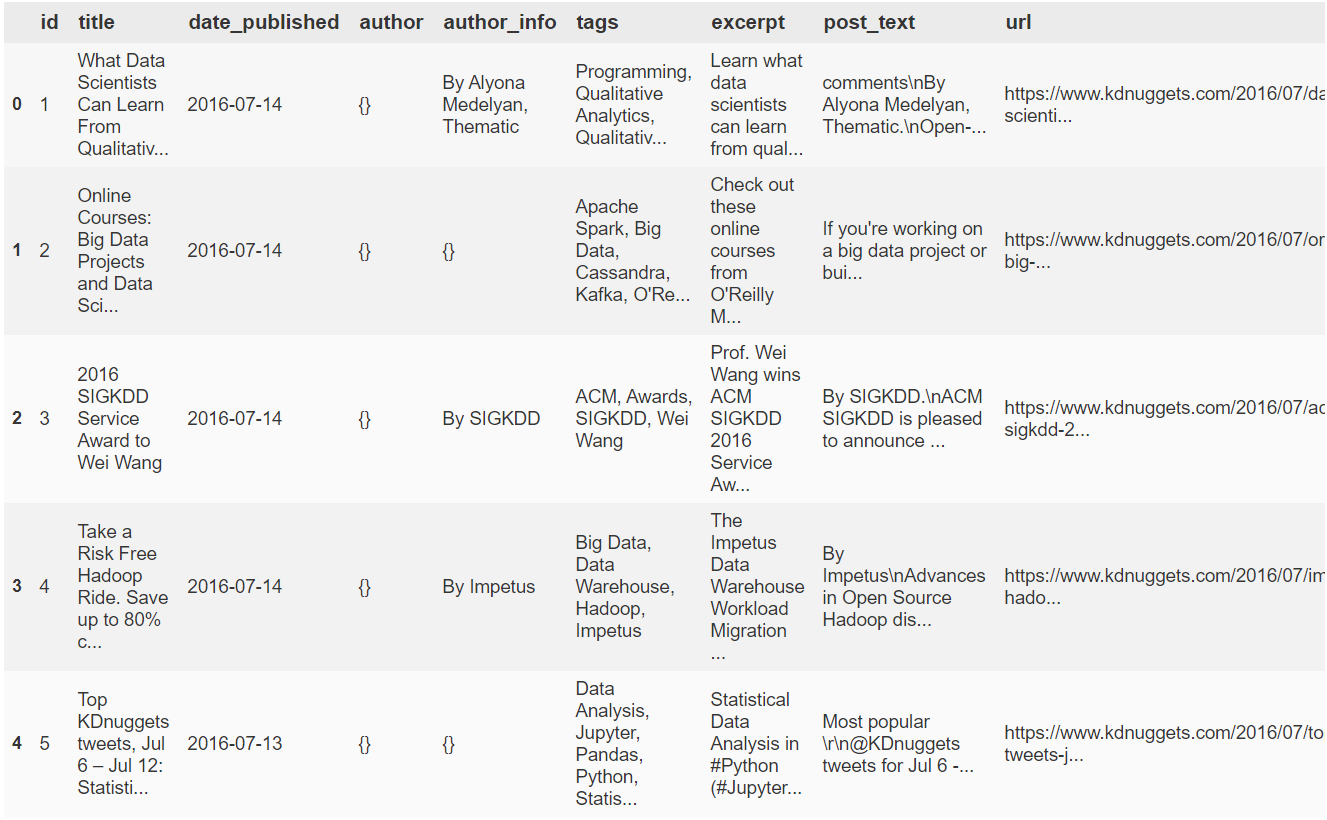
# sort by date article date and reset index
articles = kdn_articles_df.sort_values(by=['date_published'])
articles.reset_index(drop=True, inplace=True)
# We don't need the original id column anymore
articles.drop(columns=['id'], inplace=True)
articles.head()
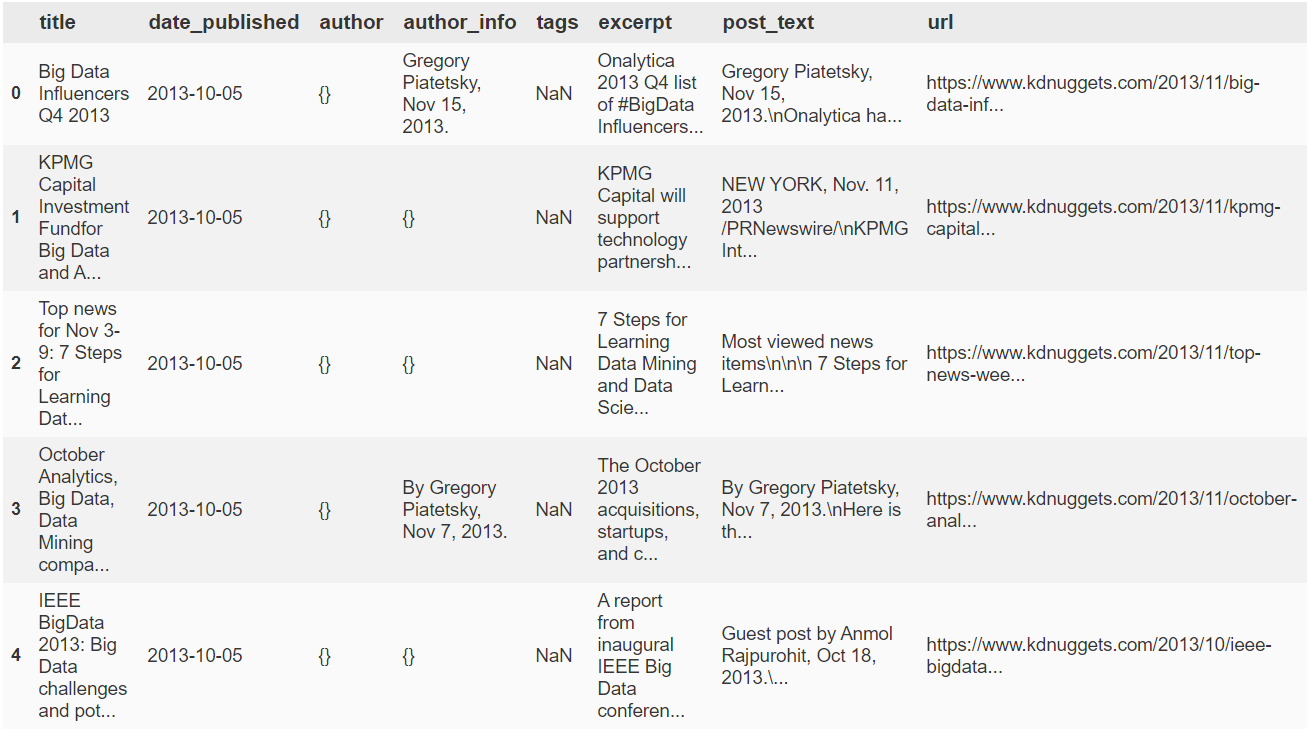
Note that earlier articles did not have tags associated with them, and often no listed authors
This concludes the module on scraping KDNuggets articles. The truth is we can build a different spider to take less recent articles, as the format of the website changes enough to warrant a different item collection strategy when you go far enough back in time, but past articles are more job listings, etc., and don't have tags which we're going to take advantage of in a subsequent module. Nonetheless we obviously don't need to limit ourselves to this small a dataset, and this has been a simple example to illustrate the general process of web scraping and the basics of SQLAlchemy.
The next post relating to kdn articles will be text cleaning, with text analysis and topic modeling to follow. My intention is to work mostly on NLP-related projects for this site, so more scraping or crawling and handling of greater quantities of textual or spoken data may very well be on the way.